
As background we first need a generic distinction between content and format.
Imagine you are in an unfamiliar city and are trying to get to the central station.
A stranger offers you two routes. Each route could be represented by a distinct line
on a paper map. The difference between the two lines is a difference in content.

Each of the routes could alternatively have been represented by a distinct series
of instructions written on the same piece of paper; these cartographic and
propositional representations differ in format. The format of a representation
constrains its possible contents. For example, a representation with a cartographic
format cannot represent what is represented by sentences such as `There could not be a
mountain whose summit is inaccessible.'\footnote{ Note that the distinction between
content and format is orthogonal to issues about representational medium. The maps in
our illustration may be paper map or electronic maps, and the instructions may be spoken,
signed or written. This difference is one of medium.} The distinction between content and
format is necessary because, as our illustration shows, each can be varied independently
of the other.

Format matters because only where two representations have the same format can they be straightforwardly inferentially integrated.
To illustrate, let’s stay with representations of routes.
Suppose you are given some verbal instructions describing a route. You are then shown a representation of a route on a map and asked whether this is the same route that was verbally described. You are not allowed to find out by following the routes or by imagining following them.
Special cases aside, answering the question will involve a process of translation because two distinct representational formats are involved, propositional and cartographic. It is not be enough that you could follow either representation of the route. You will also need to be able to translate from at least one representational format into at least one other format.

How in general can we identify or distinguish representational formats? Because representational formats are typically associated with characteristic performance profiles, it is sometimes possible to infer similarities and differences in representational format from similarities and differences in the processes in which representations feature.
To illustrate, suppose that you have a route representation and I want to work out whether it this representation has a cartographic or propositional format. One way to do this might be to test your performance on different tasks. If the representation is propositional you are likely to be relatively fast at identifying key landmarks but relatively slow at translating the route into a sequence of compass directions; but the converse will be true if your representation is cartographic.

The same principle---distinguishing and identifying formats by measuring characteristic processing
profile---works for mental representations too.
To illustrate, compare imagining seeing an object moving with actually seeing it move.
For this comparison we need to distinguish two ways of imagining seeing. There is a way of
imagining seeing which phenomenologically is something like seeing except that it does not
necessarily involve being receptive to stimuli. This way of imagining seeing, sometimes
called `sensory imagining', is commonly distinguished from cognitive ways of imagining
seeing which might for example involve thinking about seeing.
It is this way of imagining seeing an object move that we wish to compare with actually
seeing an object move.
Imagining seeing an object move and actually seeing an object move have similarities in
characteristic performance profile
(\citealp{kosslyn:1978_measuring}; \citealp[p.\ 99ff]{kosslyn:1994_image}; \citealp{kosslyn:1978_visual})
Imagining seeing an object move and actually seeing an object move have similarities in
characteristic performance profile. For instance, whether an object can be seen all at once depends
on its size and distance from the perceiver; strikingly, when subjects imagine seeing an object,
whether they can imagine seeing it all at once depends in the same way on size and distance
(\citealp{kosslyn:1978_measuring}; \citealp[p.\ 99ff]{kosslyn:1994_image}).
Also, how long it takes to imagine looking over an object depends on the object's subjective size in
the same way that how long it would take to actually look over that object would depend on its
subjective size \citep{kosslyn:1978_visual}.
The similarities in characteristic performance profile and the particular patterns of interference
are good (if non-decisive) reasons to conjecture that imagining seeing and actually seeing involve
representations with a common format.
The way imagining performing an action unfolds in time is
similar in some respects to the way actually performing an action of the same type would unfold
\citep{decety:1989_timing, decety:1996_imagined, Jeannerod:1994oz, parsons:1994_temporal,
frak:2001_orientation}
One way of imagining action is phenomenologically something like acting except
that such imaginings are not necessarily responsive to the features of actual
objects and do not necessarily result in bodily movements.
There is evidence that the way imagining performing an action unfolds in time is
similar in some respects to the way actually performing an action of the same type would unfold.
For instance, how long it takes to imagine moving an object is closely related to
how long it would take to actually move that object \citep{decety:1989_timing,
decety:1996_imagined, Jeannerod:1994oz}.
In addition, for actions such as grasping the handle of a cup, manipulating the
target object in ways that would make the action harder (such as orienting the cup's
handle to make it less convenient for you to grasp) make a corresponding difference to
the effort involved in imagining performing the action \citep{parsons:1994_temporal,
frak:2001_orientation}.
Contrast imagining rotating a ball with imagining seeing a ball rotate.
As is implied by what we’ve already said, these have quite different characteristic performance
profiles.
How quickly the former can be done is a function of how long it would take the agent to rotate the
ball, whereas how quickly the latter can be done depends on how rapidly the ball can rotate and
still be perceived as rotating.
Further, in some cases rotating a ball clockwise is easier than rotating it anti-clockwise, and so
is imagining a ball rotate. By contrast, the effort involved in actually seeing or imagining seeing
a ball rotate does not similarly differ depending on direction.
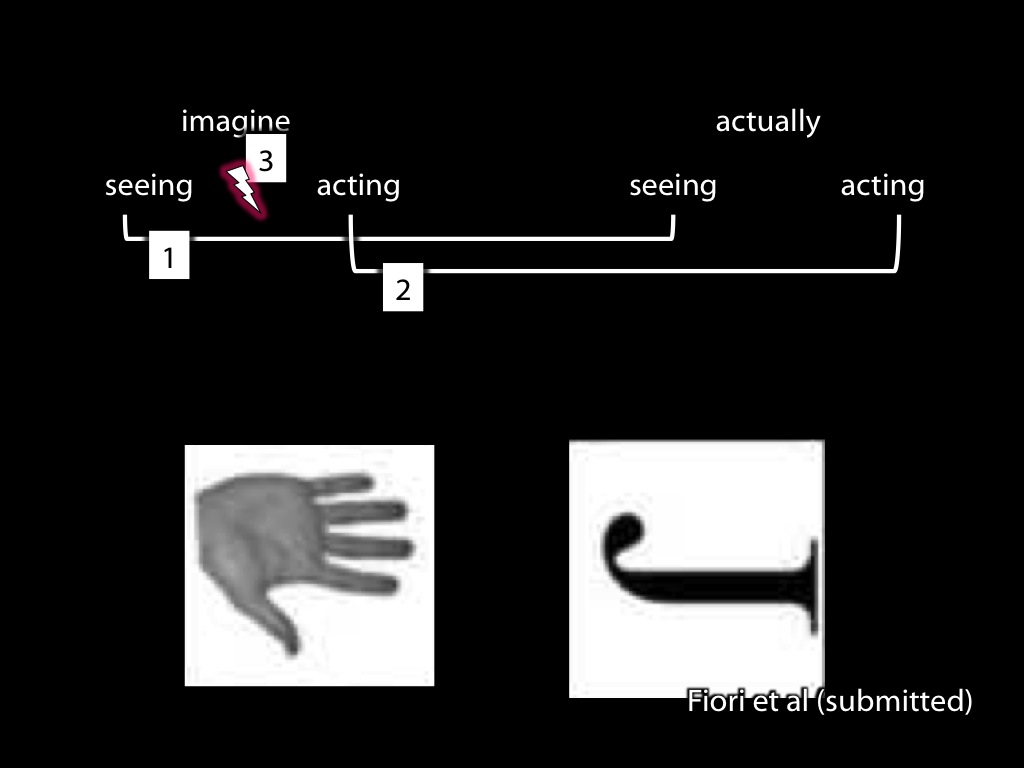
Judging the laterality of a hand vs of a letter.
For ordinary subjects, the tasks differ: they are less accurate
when the hand's position is biomechanically awkward.
But \citet{Fiori:2012fk} show that the tasks do not so differ for subjects suffering Amyotrophic
Lateral Sclerosis (ALS), which impairs motor representation \citep{parsons:1998_cerebrally}.
It may be objected that performance differences such as these can be explained without appealing to
a difference in format. After all, rotating a ball involves an action whereas a ball rotating does
not; consequently, imagining the former may be thought to differ from imagining the latter with
respect to the contents of the representations involved. Supposing that there are differences in
content here and in other cases, could these fully explain differences in performance profile? To
see why not, consider two tasks involving mental rotation. Judging the laterality of a rotated
letter is thought to involve phenomenologically vision-like imagination
\citep{jordan:2001_cortical}, whereas judging the laterality of a rotated hand is thought to involve
phenomenologically action-like imagination \citep{parsons:1987_imagined, gentilucci:1998_right}.
Ordinary subjects who are asked to judge the laterality of a hand rotated to various degrees are
less accurate when the hand's position is biomechanically awkward. By contrast, no such effect
occurs for comparable tasks involving letters rather than hands. How could this difference in
performance in imagining hands and letters be explained? Consider the claim that the difference in
performance can be fully explained by a difference in the content of the representations involved.
Initially this might seem plausible because one task involves hands whereas the other involves
letters. However, there are subjects who can perform both tasks but whose performance is not
different for hands and letters \citep{Fiori:2012fk}. These are subjects suffering Amyotrophic
Lateral Sclerosis (ALS), which impairs motor representation \citep{parsons:1998_cerebrally}. Since
ALS and ordinary subjects encounter the same stimuli and perform the same tasks, there seems to be
no reason (other than our hypothesis about a difference in format) to suppose that the two groups'
performance involves representations with different contents. So if the hand-letter difference in
performance were entirely explained by a difference in content, we would expect ALS and ordinary
subjects to exhibit the same difference in performance. But this is not the case. This is an
obstacle to supposing that the hand-letter difference in performance in ordinary subjects could be
explained by appeal to content.
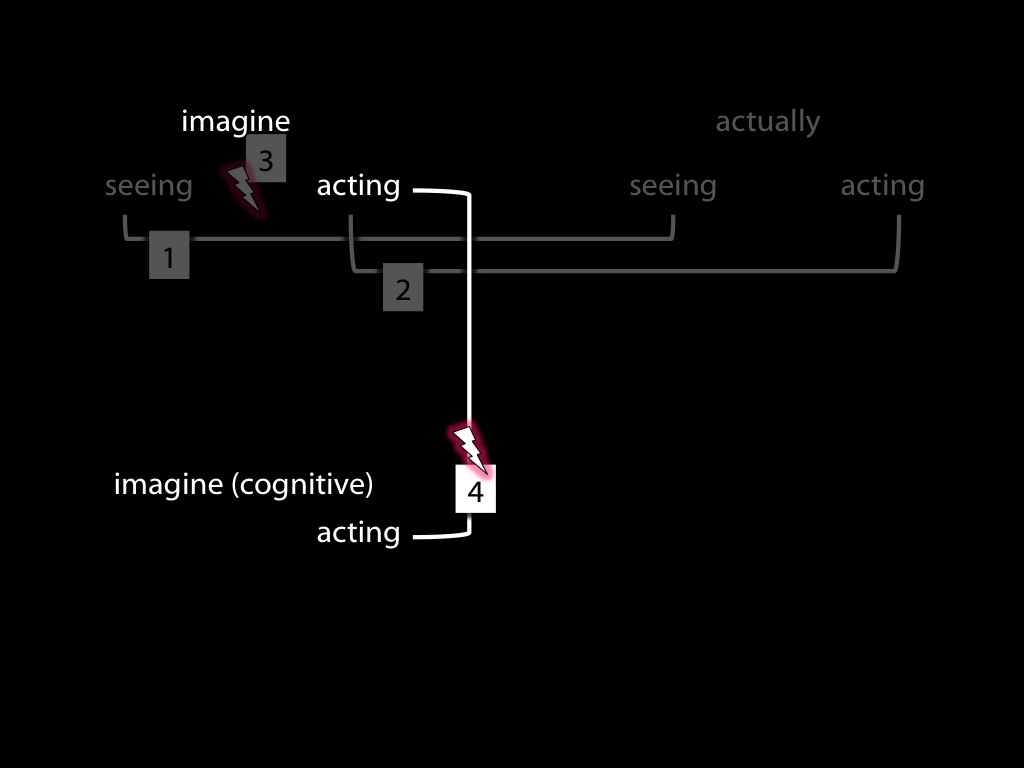
So far we have been arguing that motor and visual representations differ in format. Why suppose that
motor representations also differ in format from intentions? Contrast two ways of imagining taking a
shot in basketball, one involving the phenomenologically action-like kind of imagination and the
other involving a cognitive kind of imagination. The contrast we require is roughly between the way
a former player might imagine this and the way that someone who has only ever read about basketball
might imagine it. As we have seen, the way phenomenologically action-like imagination unfolds in
time and the amount of effort it involves will depend on bio-mechanical, dynamical and postural
constraints, among others. These constraints are closely related to those which govern actually
performing such actions \citep{Jeannerod:2001yb}, and some can be altered by acquiring or losing
motor expertise. By contrast no such constraints would be expected always to apply where a cognitive
kind of imagination is involved. In line with the general strategy of inferring differences in
format from differences in characteristic performance profile, we conclude that motor
representations differ in format from those involved in cognitive kinds of imagination, which are
plausibly propositional.